TextGrad: 自然言語フィードバックによる最適化手法の解説と、従来型機械学習との違いに関する考察
論文:TextGradの紹介と、従来型機械学習との違いに関する考察
TextGrad: 自然言語フィードバックによる最適化手法の解説と、従来型機械学習との違いに関する考察
はじめに
近年、大規模言語モデル(LLM)の飛躍的な発展に伴い、複数のLLMや外部ツールを組み合わせた「複合AIシステム」が登場し、様々な分野でその能力を発揮し始めています。このようなシステムの開発においては、プロンプト最適化や自己改善型アプローチが重要な役割を担っています。従来、self-refineやreflectionといった手法が提案されてきましたが、これらは問題解決の各フェーズで個別のヒューリスティックな調整が必要であり、プロセスが分断されがちで、システム全体を統一的に最適化するフレームワークの確立は容易ではありませんでした。
そこで提案されたのが 「TextGrad」 です。TextGradは、ニューラルネットワークにおける自動微分の枠組みを自然言語フィードバックに応用し、複合AIシステムの全体最適化を目指す、新しい最適化アプローチです。論文だけでなくライブラリとしてOSSで公開されています。本記事では、TextGradの基本概念を解説するとともに、従来手法との比較、LLMのファインチューニングや強化学習との違いを議論します。さらに、TextGradの有効性を検証するための課題と、今後の展望についても考察します。
1. TextGradの基本概念
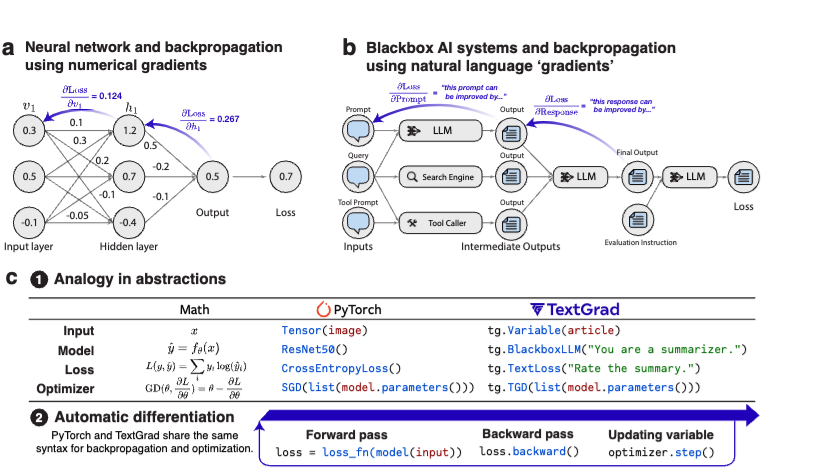
TextGradは、従来の数値勾配による最適化手法(例:誤差逆伝播法)の考え方を応用し、自然言語によるフィードバック、すなわち**「テキスト勾配」** を用いる点が最大の特徴です。
1.1 AIシステムを計算グラフとして表現
TextGradでは、最適化対象のAIシステムを計算グラフとして表現します。計算グラフは、入力、出力、中間変数を表すノードと、それらを結ぶ関数呼び出し(エッジ) から構成されます。例えば、質問応答システムの場合、「質問」「プロンプト」「回答」「評価」などが各ノードとして扱われ、これらの間の関係性がグラフ構造で定義されます。
1.2 テキスト勾配:自然言語によるフィードバック
TextGradの核となるのが 「テキスト勾配」 の概念です。各ノード(変数)に対して、LLMから生成される自然言語フィードバックを「テキスト勾配」と定義します。これは、ある変数の値をどのように変更すればシステム全体の性能が向上するかを示す、自然言語による具体的な改善案です。
テキスト勾配の導出 (論文中の式4, 5, 6を参考に説明):
例えば、以下のようなシンプルなシステムを考えます。
プロンプト + 質問 --> LLM --> 予測 --> LLM --> 評価ここで、プロンプト を最適化したい変数とします。TextGradでは、まず 予測 に対するフィードバックを求めます。これは論文中の式(4)に対応します。
∂評価/∂予測 = ∇LLM(予測, 評価)ここで、∇LLMはLLMを用いた勾配演算子で、以下のようなプロンプトで実現されます(論文中の式(6)を参考に簡略化)。
"以下の予測に対する評価が与えられます。予測を改善するためのフィードバックを提供してください。\n\n予測: {予測}\n評価: {評価}"次に、プロンプト に対するフィードバックを求めます。これは論文中の式(5)に対応します。
∂評価/∂プロンプト = ∂評価/∂予測 ∘ ∂予測/∂プロンプト = ∇LLM(プロンプト, 予測, ∂評価/∂予測)ここで、∇LLMは以下のようなプロンプトで実現されます。
"以下の質問に対する、プロンプトとそれに基づく予測、そして予測に対するフィードバック(∂評価/∂予測)が与えられます。評価を改善するためにプロンプトをどのように修正すべきか、フィードバックを提供してください。\n\n質問: {質問}\nプロンプト: {プロンプト}\n予測: {予測}\n予測へのフィードバック: {∂評価/∂予測}"このように、LLMに具体的なコンテキストと改善目標を与えることで、自然言語によるフィードバック、すなわち「テキスト勾配」を導出します。
1.3 逆伝播とTextual Gradient Descent
TextGradでは、出力側から入力側へテキスト勾配を逆伝播させ、各ノードの最適な更新を行います。具体的には、各ノードで取得された複数のフィードバックを統合し、Textual Gradient Descent(TGD) と呼ばれるオプティマイザによって変数の更新を実施します。
TGDによる変数更新 (論文中の式8, 9を参考に説明):
TGDは、現在の変数の値とテキスト勾配を入力として受け取り、更新された変数の値を生成します。これもLLMを用いて実現され、例えば以下のようなプロンプトが用いられます(論文中の式(9)を参考に簡略化)。
"以下の変数に対する現在の値と、それに対するフィードバック(∂ℒ/∂x)が与えられます。フィードバックを反映した新しい変数の値を生成してください。\n\n変数: {x}\nフィードバック: {∂ℒ/∂x}"LLMは、この指示に従い、フィードバックを反映した新しい変数の値を生成します。
複数サンプルを用いた更新(論文中のコードスニペット2を参考に説明):
実際には、TextGradは複数のサンプルから得られた損失を合計して、変数更新を行います。以下は、プロンプト最適化における、バッチ処理を用いた更新のコード例です(論文中のコードスニペット2を参考に修正)。
import textgrad as tg
# システムプロンプトを初期化
system_prompt = tg.Variable("あなたは役立つ言語モデルです。ステップバイステップで考えてください。",
requires_grad=True,
role_description="言語モデルへのシステムプロンプト")
# プロンプトによってパラメータ化されたモデルオブジェクトを設定
model = tg.BlackboxLLM(system_prompt=system_prompt)
# オプティマイザを設定
optimizer = tg.TextualGradientDescent(parameters=[system_prompt])
# 最適化ループ
for iteration in range(max_iterations):
batch_x, batch_y = next(train_loader) # バッチデータを取得
optimizer.zero_grad()
# 順伝播
responses = model(batch_x)
losses = [loss_fn(response, y) for (response, y) in zip(responses, batch_y)]
# 損失の合計を計算
total_loss = tg.sum(losses)
# 逆伝播と勾配計算
total_loss.backward()
# プロンプトの更新
optimizer.step()この例では、train_loader からバッチデータを取得し、それぞれのサンプルについて loss_fn で損失を計算しています。そして、tg.sum(losses) によって損失の合計を計算し、total_loss.backward() を呼び出すことで、バッチ全体に対するテキスト勾配を計算しています。これにより、複数のフィードバックを考慮した、より安定した更新が可能になります。
このプロセスを繰り返すことで、システム全体が一貫した方向性のもとに改善されていきます。 ただし、このsumは単純にプロンプトに複数サンプルを入力することによって行なっており、各勾配系さんなどでのプロンプトが膨れ上がるという問題があり、こういった細かな点はまだまだ改善の余地がありそうです。
2. 従来手法との比較:実験結果に基づく優位性
論文では、TextGradの有効性を示すために、複数のタスクにおいて従来手法との比較実験が行われています。ここでは、その結果に基づいてTextGradの優位性を解説します。
2.1 コード最適化 (LeetCode Hardデータセット)
- タスク: LeetCode Hardデータセットを用いた、難しいコーディング問題のコード最適化。
- 評価指標: 完了率 (与えられた問題のすべてのテストケースをパスする割合)。
- 従来手法:
- GPT-4 ゼロショット: 完了率 23%
- Reflexion (1デモンストレーション、5イテレーション): 完了率 31%
- TextGrad: ゼロショット設定 (デモンストレーションなし) で5回のイテレーションを実行し、完了率 36% を達成。
- 優位性: TextGradは、デモンストレーションなしで、Reflexion (デモンストレーションあり) を上回る性能を達成しており、その効果の高さが示されています。
2.2 質問応答 (Google-proof QA, MMLU)
- タスク: 科学的な質問 (Google-proof QA、MMLU-Machine Learning、MMLU-College Physics) に対する解答の最適化。
- 評価指標: 正答率。
- 従来手法:
- Google-proof QA:
- CoT (Chain-of-Thought) プロンプティング: 51.0%
- 報告されている最高精度 (gpt-4o): 53.6%
- MMLU-Machine Learning:
- CoT プロンプティング: 85.7%
- MMLU-College Physics:
- CoT プロンプティング: 91.2%
- Google-proof QA:
- TextGrad: gpt-4oを使用し、3回のテスト時更新を実施。最終回答はすべてのソリューションの多数決で決定。
- Google-proof QA: 55.0% (報告されている最高精度を更新)
- MMLU-Machine Learning: 88.4%
- MMLU-College Physics: 95.1%
- 優位性: TextGradは、最も高性能なモデルであるgpt-4oの性能をさらに向上させ、特にGoogle-proof QAでは報告されている最高精度を更新しています。
2.3 プロンプト最適化 (Big Bench Hard, GSM8k)
- タスク: 推論タスク (Big Bench Hard、GSM8k) において、LLM (gpt-3.5-turbo-0125) のパフォーマンスを向上させるプロンプトの最適化。
- 評価指標: タスクに応じた精度 (例: Object Counting と GSM8k は完全一致精度、Word Sorting は LLM による評価)。
- 従来手法:
- ゼロショット CoT プロンプティング
- DSPy (最先端のプロンプト最適化フレームワーク)
- TextGrad: gpt-4oをフィードバック生成に使用し、バッチサイズ3、12イテレーションで最適化を実施 (合計36のトレーニングサンプル)。
- Object Counting: 91.9% (DSPy を 7% 上回る)
- Word Sorting: 79.8% (DSPy と同等)
- GSM8k: 81.1% (DSPy と同等)
- 優位性: TextGradは、ゼロショットのプロンプトの性能を大幅に向上させ、DSPyと同等またはそれ以上の性能を達成しています。特に、Object Countingタスクでは、DSPyを7%上回る精度を達成しており、TextGradの有効性を示しています。
これらの実験結果から、TextGradは、コード最適化、質問応答、プロンプト最適化といった多様なタスクにおいて、従来手法を上回る性能を達成できることが示されています。
3. LLMの数値ロスに基づく最適化手法との違い
従来のLLMのファインチューニングや強化学習では、最終的なロス関数が数値として定義され、その勾配をもとにパラメータ更新が行われます。一方、TextGradは以下の点で異なります。
3.1 数値ロス不要の柔軟性
従来手法では、最終的な判断がスカラー値のロスに依存するため、多次元的で複雑な改善要素を一つの数値に圧縮せざるを得ません。一方、テキスト勾配は、自然言語を通じて多様な観点からの改善情報(具体性、論理性、表現の明瞭さなど)を同時に捉えることができるため、1回の更新でより豊かで多角的な情報を活用できます。
- 具体例:
- 自然言語による指定: 目的を自然言語で記述し、それをLLMへのプロンプトとして与えることで目的関数を定義できます(3.3章で例示)。
- コードインタープリタの出力: コードインタープリタに単体テストを実行させ、その出力を目的関数として使用できます(3.1章で例示)。
- 分子シミュレーションエンジンの出力: 分子シミュレーションエンジンの出力を目的関数として使用できます(3.4章で例示)。
- コードスニペットの評価例:
この例では、LLMにコードスニペットとその目標を与え、正確性と実行時計算量を評価させています。この評価結果を基に、コードスニペットを最適化できます。これは、LLMが人間のフィードバックを模倣し、自己評価、自己改善する能力を持つことを活用しています。
Loss(code, target goal) = LLM("コードスニペット: {code}、目標: {target goal}。このスニペットを正確性と実行時計算量の観点から評価してください。")
3.2 ヒューリスティックな探索への寄与
数値勾配ベースの手法は、局所的な最適解の探索には有利ですが、未知の表現空間での探索や大まかなヒューリスティックな改善には不向きな場合があります。TextGradは、自然言語によるフィードバックを用いることで、より柔軟な探索を可能にし、ヒューリスティックな改善を実現しやすくします。 ただし、微細な数値的最適化には依然として向かない側面もあり、タスクの特性に合わせた使い分けが重要です。 TextGradでは、LLMに評価や改善指示を与えることで、従来の数値的なロス関数では捉えきれない、より高度な最適化を促せる点が強みです。
まとめと今後の展望
TextGradは、LLMが生成する自然言語フィードバックを活用することで、従来の数値勾配に依存しない新たな最適化パラダイムを提案しています。以下のポイントが個人的には特に注目ポイントとなります。
- 統一的な計算グラフの枠組みにより、self-refineやreflectionといった手法を包含し、全体の複雑性を低減できる可能性
- 数値ロスに依存せず、自然言語のリッチな改善情報を直接活用することで、ヒューリスティックな探索や柔軟な最適化を実現する可能性
おわりに
本記事では、TextGradの基本概念、技術的意義、従来手法との違い、そして今後の課題について解説しました。LLM開発者としては finetuningやRLに目を向けがちですが、LLMを用いたテキスト空間での最適化というのは、従来の機械学習で話し得なかったような柔軟性やヒューリスティックな探索を実現する可能性があり、さまざまな可能性を秘めているのではないかと、個人的に期待しています。ライブラリの完成度などまだまだ課題は多そうですが、有象無象のプロンプトテクニックがある中統一的な見方を持っていると、これらのテキストベースの最適化の見通しをより良くできると思います。